Everything you need
Built for real interviews
Every feature designed around one goal: give you the answer before the silence gets awkward.
On-device STT
Whisper runs locally — MLX on Apple Silicon, openai-whisper on Windows. Zero API keys required for transcription. Works fully offline.
Conversation memory
Remembers the last 3–5 Q&A pairs. Follow-up questions like 'what are its features?' work correctly.
Streaming AI overlay
Answers stream as bullet points in real time into a frameless, always-on-top Electron window — right when you need them.
Screenshot analysis
Drop a screenshot and the app OCRs it with Tesseract + AI for instant analysis. Great for coding problems on screen.
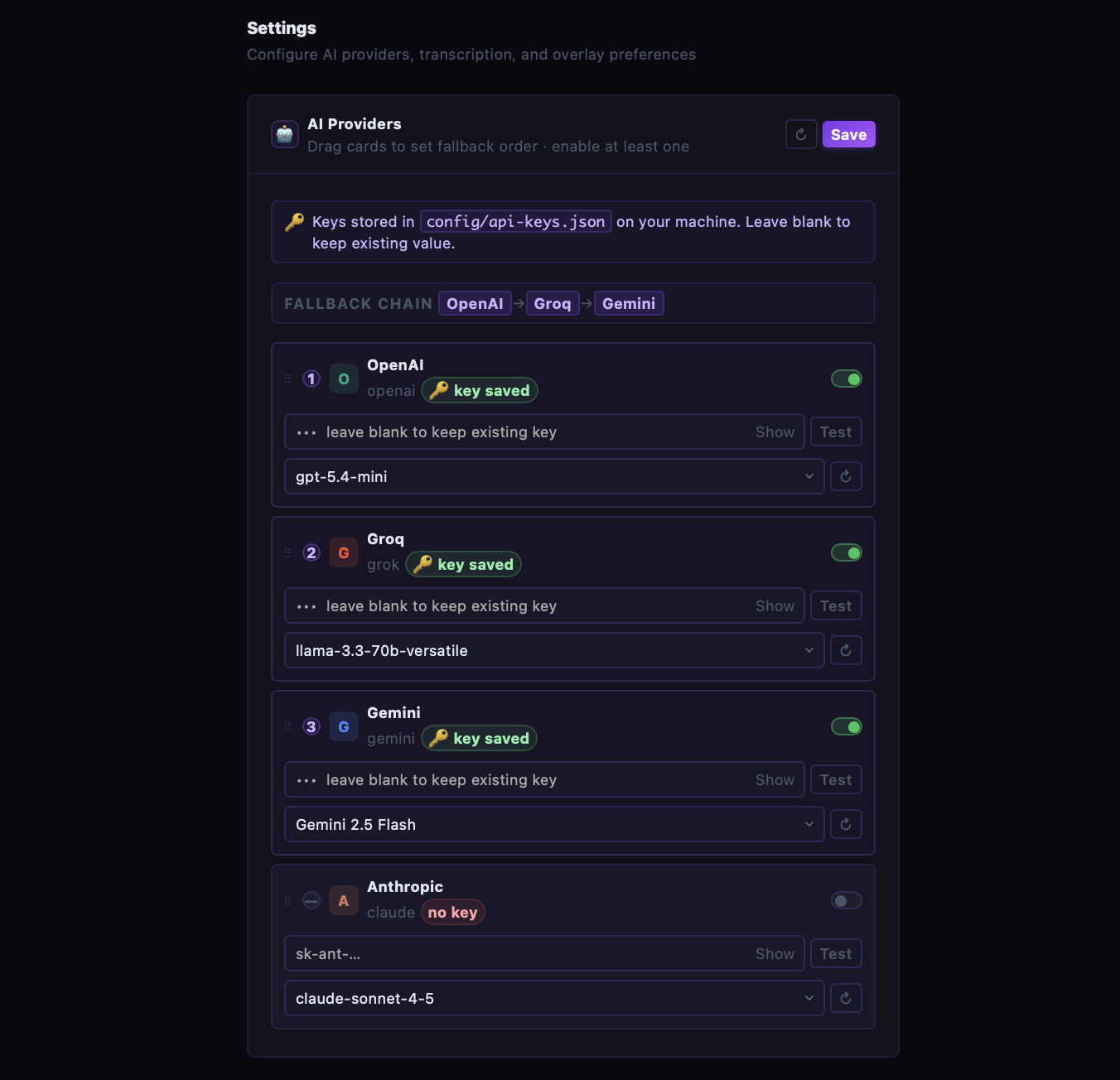
Multi-provider fallback
Configure OpenAI → Groq → Gemini → Claude as a cascade. If one fails or rate-limits, the next kicks in automatically.
Grafana observability
OpenTelemetry metrics and structured logs shipped to Grafana Cloud. Track AI latency, token cost, VAD, and Whisper decode times in real time.
Under the hood
How it works
Four stages, all running locally on your machine. From mic to HUD in under two seconds.
Interviewer speaks
Your microphone captures audio continuously. Silero VAD filters silence so only real speech is processed.
On-device · MLX (macOS) / CPU Whisper (Windows) · No API keyWhisper transcribes in real time
LocalAgreement-2 streaming decoder commits words every 300ms, giving you a live partial transcript as the question unfolds.
Committed words · Tentative wordsAI generates your answer
The question hits your configured AI provider chain. If one fails, the next takes over. Answers stream token-by-token.
OpenAI → Groq → Gemini → Claude → OllamaHUD shows it — only to you
Answer bullet points appear in a frameless invisible overlay. Screenshare, recording, and screenshots cannot capture it — on macOS and Windows.
setContentProtection(true)Get running in minutes
Quick start
One command installs everything. Pick your platform below.
Clone & first-time setup
Installs Homebrew, Node.js, Python, Ollama, and all dependencies automatically. MLX Whisper pre-warms on first launch.
Add your AI keys
Open the settings page and configure at least one provider. Keys are stored locally — never sent anywhere else.
Start the app
Launches Node.js backend, MLX Whisper transcriber, and the invisible Electron HUD overlay.
Shortcut keys — macOS
Your choice
Works with all major AI providers
Configure a fallback chain — if one rate-limits, the next kicks in automatically.
OpenAI
gpt-4o-mini
Groq
llama-3.3-70b
Gemini
gemini-2.5-flash
Anthropic
claude-sonnet-4-5
Ollama
llama3.2:1b (local)
Settings
Configure everything in the browser
Open http://localhost:4000/settings after starting. Keys stored locally — never sent anywhere.
Everything stays on your device
No cloud storage. No telemetry. No surprises.
Zero telemetry
No usage data, no analytics, no crash reports sent anywhere. The only outbound calls are to your own AI provider API keys.
Keys stored locally
API keys live in config/api-keys.json on your machine — gitignored by default. Never transmitted to any server we operate.
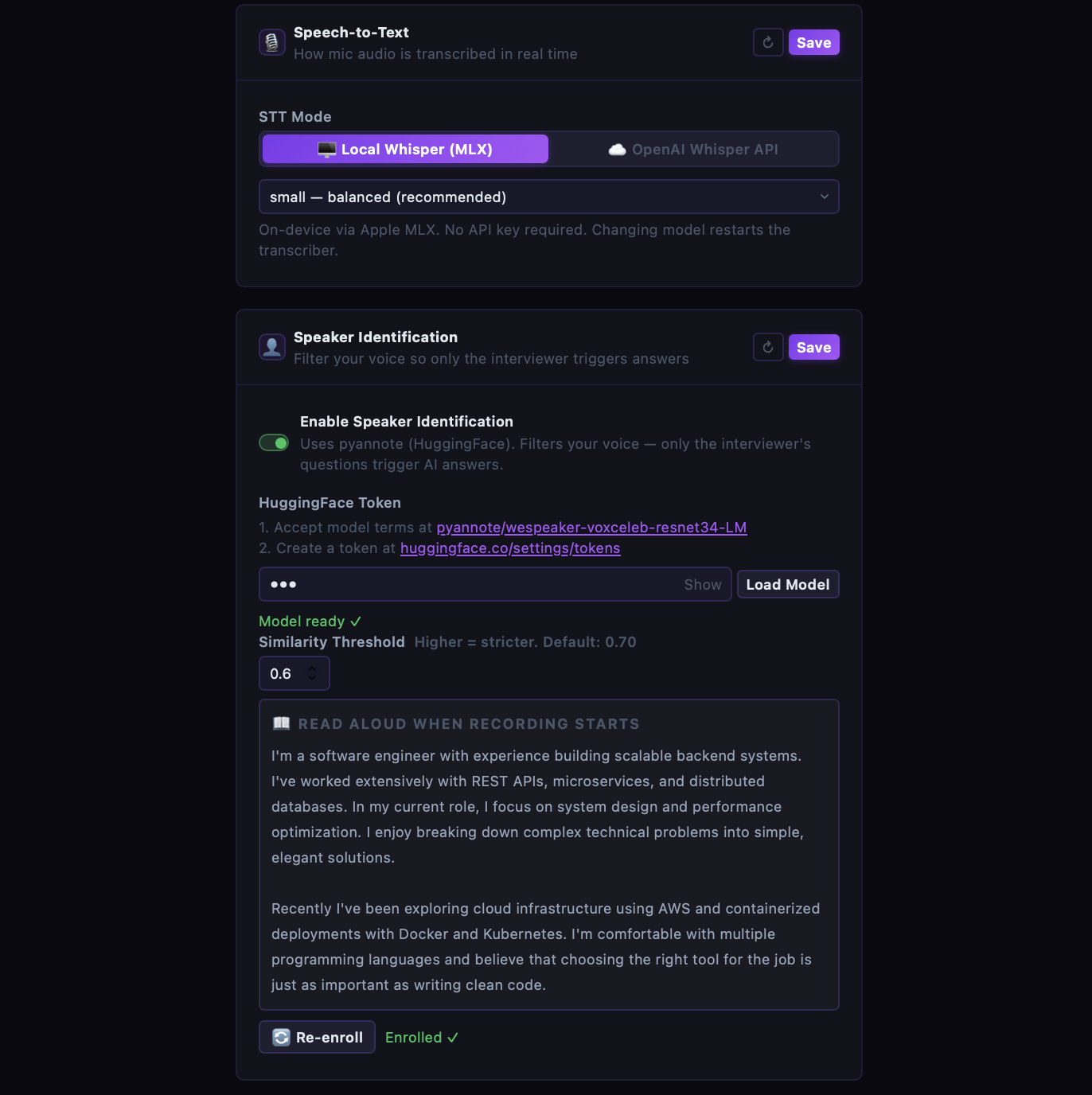
STT runs on-device
Whisper via Apple MLX processes audio locally. Your conversation never leaves your Mac unless you choose OpenAI Whisper API mode.
How we compare
SolveWatch vs Cluely vs Parakeet
The tools are similar on the surface. The differences are in cost, latency, and how much you trust a closed cloud with your interview audio.
Competitor data based on publicly available pricing and feature pages. Latency figures are approximate and vary by model and network.
Learn more
How SolveWatch actually works
Deeper guides on the invisibility layer, the latency architecture, and the full audio-to-answer pipeline.
FAQ
Common questions
Everything you need to know before installing.
The creator
About & Contact
Built by a developer who got tired of going blank in interviews.
About me
I'm a full-stack developer passionate about building tools that make developers' lives easier. SolveWatch AI was born from real interview pain — I wanted an assistant that stays invisible while actually helping.
View PortfolioGet in touch
Found a bug? Have a feature request? Want to collaborate? Drop me a message — I read every email and reply to all of them.
sparmeet162000@gmail.com